Version 1.1 beta
Peter Merel
March 28, 2000
TABLE OF CONTENTS.......................................................................................................................
1
Conventions........................................................................................................................................
2
Source Methodologies...........................................................................................
错误!未定义书签。
Development Values and Principles......................................................................................................
4
Immediate, Unquantified Requirements..................................................................................................
5
Estimation Techniques........................................................................................................................
5
Quantified Requirements: User Stories..................................................................................................
6
Iterations and Commitment Schedule....................................................................................................
9
Development Process: Overview..........................................................................................................
10
Development Process: Engineering Task.............................................................................................
10
Development Process: User Story.......................................................................................................
12
Development Process: Iteration...........................................................................................................
13
Development Process: Project............................................................................................................
14
Team Structure.................................................................................................................................
16
Appendix A: Terminology...................................................................................................................
17
Appendix B: Pathological Methodologies.............................................................................................
18
Appendix C: Pair Programming...........................................................................................................
19
Appendix D: Architecture and Patterns................................................................................................
20
References.......................................................................................................................................
21
Methodologies don’t always use the same words to mean the
same things. We use the terminology of Appendix A throughout this document.
Further definitions in the text are boldface to make them easy to locate.
UML Sequence Diagrams [1] summarize development process. Each object (box)
on these diagrams represents a development activity, and each message (arrow)
between them either an intermediary product or a deliverable. Time runs down
the vertical access. Functional responsibilities are attached to each activity
as notes; assignment of these responsibilities to team members is described
under “Team Structure”.
Introduction
No process is ideal for all situations and
goals, but two schools of methodology have a consistent history of failure.
These are extremes that drain reliability and responsiveness from development
activities. We describe them not to recommend them, but to emphasize the pitfalls
we intend to avoid.
q
Cowboy Coding is a state of affairs that survives through developer heroics and
business determination. While heroics and determination are commendable, their
daily occurrence results in poor system quality, inappropriate functionality,
low developer morale, and unpleasant surprises for users and management. Although
we call this Cowboy Coding, it’s also a failure of business process.
The accepted formal standard for evaluating
development process, the Software Engineering Institute’s Capability Maturity
Model [2], ranks methodologies on a five point scale. Cowboy Coding corresponds
with level 1, the lowest, on the SEI CMM.
q
Big Brother derives from a reaction against Cowboy Coding. It’s development by
bureaucracy. Big Brother is characterized by hierarchically delegated authority
and zero-feedback process. Neither stakeholders nor developers favor bureaucracy
in and of itself, but, under Big Brother, efforts to improve matters somehow
always result in more bureaucracy, and less quality.
Though we call it Big Brother, bureaucracy
occurs in small projects too. It can easily occur in projects with SEI CMM levels
as high as 2 or 3 when they’re afflicted with one or more of the pathologies
described in Appendix B.
Appendix B catalogs
the shortcomings of each extreme in detail.
A raft of development methods have attempted
to avoid these extremes. The most popular today are the Microsoft Solutions
Framework, or MSF [4]; Beck & Cunningham’s Extreme Programming, or XP [5];
and the Rational Unified Process, RUP [6]. Our aim in this paper is to describe
a process that combines the three into a consistent whole.
| |
MSF
|
XP
|
RUP
|
|
Pedigree
|
Formal practices applied by Microsoft’s internal development
groups and integral to MS engineering structures.
|
A movement in the Design Patterns community related
to the Crystal & Scrum methodologies. Early success at Chrysler Comprehensive
Compensation (C3). Achieved critical acclaim at the Portland Pattern
Repository. In use by groups at WyCash, First Union National Bank, CS
Life, BayerischeLandesbank, and Ford Motor Company.
|
The Objectory phased methodology updated to include
iterative elements. Applied in variations by many commercial development
groups.
|
|
Tools
and Techniques
|
Microsoft DNA/Visual Studio.
|
CRC, User Stories, Commitment Schedule
|
UML + the Rose suite of requirement, design, testing,
profiling and SCM support tools
|
|
Originators
|
MS internal groups
|
Kent Beck and Ward Cunningham, pioneers in Object Orientation
who invented the universally applied CRC design technique [8]. Also Ron
Jeffries, C3’s “Coach”.
|
The “Three Amigos” of Object Oriented software, Grady
Booch, James Rumbaugh, and Ivar Jacobsen.
|
|
Strengths
|
Closely defines business modeling
techniques, functional roles, and testing practices.
|
Details consensual project standards,
iterative design, coding and testing practices.
|
Defines UML modeling techniques,
phased development, and intermediary formats
|
|
Weaknesses
|
Doesn’t specify a step-by-step development process.
|
Neglects business modeling, architecture
and deployment activities.
|
Doesn’t support feature-driven scheduling and refactoring activities
|
·
Figure 1
XUP Source Methodologies in a Nutshell
These methodologies
are for the most part compatible, though each emphasizes different aspects of
thinking about and conducting development. Each is most effective when focused
on its intended scale of development. We see them as resolving points on a continuum
of project scope:
q
1 week 2 developer
fire-fights don’t require and can’t afford much process overhead – little more
than an XP “Engineering Task”.
q
Small projects
– teams of 2-12 developers and timeframes of 3-6 months - are best served by
the rapid but rigorous iterations defined by XP and the functional responsibilities
of MSF
q
Larger groups
and larger contexts – especially those concerned with enterprise-wide and architectural
concerns – benefit from the business modeling aspects of MSF as well as abstract
analysis tools and techniques in RUP.
MSF and XP
fit together very neatly; in fact some groups within MS have stated publicly
that they’ve gone XP. MSF conflicts in some details with RUP, but Rational are
working to resolve the disconnects [7]. Where we see clashes in the methodologies
we use practices that best fit our development values and principles.
Development
values are not goals to be achieved, but criteria to use to make decisions.
We use these values to structure our thinking about methodology and guide process
from day to day.
q
Simplicity: We continually work to make business
processes, development processes, and the systems we build as simple as they
can possibly be and still work. But no simpler.
q
Continuous Feedback: We don’t
let bad assumptions live long. We seek feedback from stakeholders and tools
as soon as possible. We prototype, measure and test.
q
Harmonious Aggressiveness: We go fast; we identify and repair anything that
stresses or slows us down. But we take care to stay open minded, impartial,
and compassionate toward each other.
q
Open Communication: We keep Business 100% aware of what we’re
doing, and why, at all times. We don’t play politics or keep secrets. We work
to resolve disconnects throughout our development process.
q
Business Negotiation: We work proactively to understand and
support the business through regular, careful, explicit negotiations. We don’t
specify or drive Business needs or priorities. Business doesn’t estimate, design,
or specify technologies for our solutions.
To secure
these values we employ a number of generic techniques. These form principles
that underlie the specific procedures and roles we define later in this document.
q
Do The Simplest Thing That Can Possibly
Work: We don’t try
to do something grand and heroic. We do something very simple that works. We
do the simplest thing that can possibly work. Nevertheless, instead of letting
this continue as Cowboy Coding, we immediately and always
refactor.
q
Refactor Mercilessly: Refactoring
is eliminating redundancy, special cases, and unnecessary interdependence. We
refactor until all the functionality in the system is coded Once And Only
Once – each element of functionality appearing in just one place in
the source. Doing this immediately and mercilessly contains source-complexity,
promotes re-use, and reduces the cost of maintenance.
q
You Aren’t Going To Need It: During any activity, the only work that
is done is work that is required right then and there, never anything that “will
be needed later”. Analysis constrains itself to specific requirements,
not completions. Design and coding are scoped to particular features, not generics.
Completeness and genericity will emerge naturally over time if we refactor mercilessly.
q
Features, Not Subsystems: Since we’re going fast, we need to make
certain that what we deliver is always something we can test. So we don’t develop
by subsystem. We develop by Feature, each of which is a thread through
all subsystems that corresponds with a concrete requirement. This way our work
is testable at all points of a project, not just a the end.
q
Continuous Integration: We use a merging rather than a locking
SCM strategy. We communicate our work with one another as soon as we possibly
can. As developers we don’t go dark for long. Left to sit alone, even the most
brilliant programming becomes prohibitively expensive to integrate.
q
Relentless Testing: The best way to facilitate Continuous
Integration is Relentless Testing. Before any component is written, a
unit test is coded first. Before any code change is checked in, all
unit tests for the whole development are run to make sure the code change doesn’t
break anything. For every significant deliverable feature we create a functional
test. And every night a “Smoke Test” is automatically performed – all unit tests
and all functional tests run – with the results graphed for management. At all
points, not just at the end of the project, we have a demonstrably functional
system.
q
Standards, Not Ownership: Our developers don’t own code. Actually
it’s more accurate to say we collectively own it. Our project standards are
a superset of enterprise standards, developed by, agreed by, and changeable
by the consensus of our developers. Our products all use the same style, so,
when refactoring, any developer can quickly and confidently alter any part of
the system.
q
Pairing and Peering: We assure maintainability through Pair
work and Peer review. Work that is produced by a pair of developers needs much
less oversight than work produced by a developer alone. Peer review is time
consuming, and can require onerous re-engineering too. So we work in pairs as
often and as closely as is comfortable. When pairing is not desirable, we require
peer review before the result is integrated with releases external to the project.
More details on Pair work are given in Appendix C.
Sometimes
we have to do things informally – we have fires to fight. We know this isn’t
smart work. Unexpected, isolated, informal, immediate requirements derive from
poor planning. They’re unsupported by architecture because our architects are
given no time to prepare for them. They occur outside proper business context
because they’re adopted as emergency measures, often without budget or discipline.
The results of working on them still have to be tested, documented, and integrated
into the main line of development, which is really painful when the work to
be integrated was done without adequate care. Regularly pursuing these requirements
places unacceptable stresses on developers too. These efforts are simply inefficient
– they have disproportionate cost for only a small return.
Immediate
requirements are nevertheless an unavoidable fact of business, and we define
a development process to deal with them. We call this process an Engineering
Task. We emphasize rigor and maintainability in these Engineering Tasks
because they also serve as the building blocks of our larger development process.
They are our atoms – the smallest units of work we expect our developers to
perform and maintain.
Any work that
cannot meet at least the minimum standards of an Engineering Task is considered
a throwaway - a spike. Sometimes we have no choice but to rush through spike,
but we always throw it away as soon as possible. We schedule Engineering
Tasks to re-engineer and integrate Spikes into our main line of development.
This discipline provides the flexibility to attack immediate requirements without
compromising project continuity, lowering efficiency or morale, or degrading
the quality of subsequent deliverables.
Working with
immediate requirements and individual Engineering Tasks provides us with no
basis for estimating budgets and timeframes. In fact one of the most common
failures of software development groups is an inability to reliably estimate
project timeframes and costs. XP estimation techniques are designed to minimize
these failures:
q
Early and continual
feedback prevents the deferral of integration, refactoring, and testing until
the end of a project, removing the risk of large surprises.
q
Estimates are
made and reviewed by developers, not managers. Because the estimators are directly
responsible for accomplishing what they estimate, our estimates better describe
capabilities and process limitations All Developers review project scope estimates
to try to improve them so the same estimating mistakes are not repeated over
and over.
q
Developers can’t estimate time taken by meetings, environmental
problems, and tool failures. Developers can’t estimate the cost of familiarizing
themselves with required tools and techniques. Developers are very poor at estimating
buffer time needed for testing, refactoring, and integration … so, we don’t
make developers guess these things. Instead, we measure them.
To measure
the things developers can’t estimate, MSF and XP both advise the use of two
schedules. One is internal, estimated in terms of Ideal Days where
tools and designs are perfect, there are no interruptions, and everything flows
smooth as silk. In practice these Ideal Days never occur, so our other schedule
is the external one, the one Customers can rely on. The external schedule
is obtained by measuring the ratio of typical past Ideal estimates to past performance
and multiplying Ideal Days by this ratio to obtain Real Days. The ratio
of Real Days to Ideal Days is called the Load Factor, and we apply it
regularly and consistently in our external estimates.
Load Factor
isn’t a measurement of efficiency per se. It’s more like the degree to which
we tend to over-estimate our abilities. It measures our optimism. The change
in Load Factor over Iterations, however, can reflect changes in development
efficiency, and should be tracked and analyzed carefully.
For initial
estimates we can’t use a measured Load Factor because we have no Iteration history
to measure. We could start with any Load Factor we please, so long as we’re
consistent with the amount of work we estimate can be done in an Ideal Day.
In practice it’s standard to use a Load Factor of 3 for initial estimates. As
soon as possible we replace that with the directly measured quantity.
Our period
of measurement is a fixed timeframe of 3 Real Weeks that we call an Iteration.
To understand
all this, consider a project with 5 developers about to enter its second iteration.
The first Iteration’s Load Factor is 3. Real Days Expected for the first Iteration
was 5 developers x 15 real days = 75 Real Days. In fact it turns out that when
we complete the initial iteration we deliver User Stories that were estimated
with the initial Load Factor to be worth 90 Real Days.
So our second
iteration’s measured Load Factor is 2.5. Therefore we can schedule 30 Ideal
Days of User Stories to fit into it. If this Load Factor keeps up for a few
Iterations, we’ll want to use the rescheduling strategies described in the section
on “Commitment Schedule” below to recalculate the remaining Project scope.
Because we
know how many Ideal Days we expect to fit into in a Real Iteration, we know
how many features we expect to deliver in a Real Iteration. By tracking the
completion of each feature we get a value for the Real Days accomplished in
each Iteration, and that’s the value we use to figure out the Load Factor to
use in the next Iteration.
We graph Load
Factor over the project’s whole life. We must be careful not to misinterpret
Load Factor as a quality that can be specified rather than measured. We
can tell developers, "work harder and smarter”, but it makes no sense
to say, "the Load Factor is now set at 0.5. See that it stays that way”.
Load Factor is feedback for the purpose of management, not a dial that can be
turned to speed anything up.
A User Story is a feature that’s
been fully quantified by Customers, properly estimated by Developers, and which
is no larger than a certain size. We use User Stories to determine what needs
to be done and when.
Why not just combine Engineering Tasks
arbitrarily? Well, business priorities can’t be ranked if requirements just
dribble in as they emerge. Architectural decisions can’t be made without gauging
a project’s scope. Functional tests can’t be developed without a concrete understanding
of each requirement’s priority and qualities. Budgets aren’t realistic without
understanding the relationship between scope and timeframe.
So, for a project larger than fire-fight,
requirements have to be proactively gathered, quantified, approved and prioritized
by a consistent process. This quantification work should be explicitly negotiated
between Customers and Development in terms that are meaningful to both. And
each requirement has to be reduced to a manageable granularity in order for
estimates to obtain confidence and realism. If we do all that, what we get is
what we call a User Story.
·
Figure 2 Quantifying a User Story.
q
Need: Customers specify
a business need; Development clarifies it by modeling. User Stories can be functionally
specified in one of three forms, each with a progressively greater level of
detail and accompanying maintenance burden. In practice we choose the simplest
form that achieves a concrete shared understanding between Customers and Developers.
n
User Stories that are well understood by both Customers
and Developers are summarized with a few sentences of English text.
n
User Stories that are not well understood by Customers,
or that Developers feel have redundant or questionable content, are also described
by User Stories, but these User Stories are further explored via CRC business
modeling [8]. CRC involves role-playing a User Story to discover external
actors, internal objects, their responsibilities and necessary collaborations
between them. The common understanding achieved by CRC can be recorded as Use
Case Diagrams in the standard RUP diagram language, UML [9]. Use Case Diagrams
can be combined and split apart to refactor User Stories until they’re the right
size.
n
Use Cases that don’t obviously relate to known architectural
elements can be further detailed by Developers and Architects using CRC for
Analysis and Design purposes, and the results can be recorded as UML Collaboration
Diagrams [10] and Sequence Diagrams. Collaboration Diagrams show
the functional interdependencies necessary for objects to reproduce the Story;
Sequence Diagrams map these functional interdependencies into the Story’s time
order. Architectural refinement of these diagrams is detailed by architects
using UML Class Diagrams [11]. Class Diagrams show is-a, has-a, containment,
indexing, and usage relationships between objects. Implications of all these
diagrams can propagate up to the corresponding Use Cases.
We
use only those forms necessary to achieve a concrete common understanding between
Customers and Developers, and no more. The maintenance burden
of unnecessary intermediary products is a prime contributor to the Big Brother
pathologies described in Appendix B.
These
three forms are all functional specifications of a User Story. But even the
most detailed functional specifications, by themselves, are inadequate for estimation
purposes. As User Stories are functionally quantified, they must also be quantified
in the three non-functional dimensions.
q
Quality: Customers specify
this too. Quality answers questions like:
n
How fast?
n
How many?
n
How secure?
n
Etc.
Customers quantify
only Qualities they feel are relevant to a User Story. Required Qualities may
change over time as User Stories are tested and reviewed, so Customers don’t
have to get all these Qualities specified exactly right up front – we revisit
Customer estimates as often as every Iteration if need be. But Quality
is not something we can easily reverse-engineer, so the Qualities of User Stories
that have already been delivered can’t be requantified after the fact. Instead,
new User Stories must be introduced to account for the late change in Customer
requirements. A project never revisits Quality estimates more often than once
an Iteration, or else the development becomes unmanageable.
q
Priority: Customers
specify this as well. Initially, they just sort User Stories into 3 piles:
n
Must
Be Done Or The System Fails: These User Stories are the real reason
Customers want this system. If you can’t deliver these, you may as well forget
the whole thing.
n
Must
Be Done Or We Lose Market Share: Customers can get by without these User
Stories, but it’ll hurt a lot. Customers have to do a lot of extra work without
them. If somehow they can’t be delivered this project, they’ll have to be done
soon after or there’ll be big trouble.
n
We
Really Want The System To Do This If Possible: We know development
can’t do everything, but we’d be delighted and thrilled if you could deliver
these. If you get the stuff in the first two piles finished, please try to make
these User Stories happen too.
Next, Customers order the contents of
each pile into a continuum in order of priority, most important first. Customers
don’t have to get all this right up front – like Qualities, Priorities can be
adjusted as often as every 3 weeks throughout the life of the project. But no
more often than that.
q
Scope: Developers estimate
this in Ideal Days. In order to do so, they sort User Stories into 4 piles:
n
Developers
Know Exactly How To Do This, And It’ll Take Less Than 3 Ideal Weeks.
A firm estimate is calculated, reviewed by all developers, and attached to the
User Story.
n
The Best Estimate Of Developers Is More Than 3 Ideal Weeks. Developers can’t
estimate Scope with enough confidence to be sure. Our understanding is too vague or the User Story is too big. Take
the Story back to the Customers and split it into smaller pieces until it can
be stuck in the first pile.
n
Developers
Don’t Know Exactly How To Do This. Customers and Developers
meet for CRC to build Use Cases. If Developers figure a good way to work, they
stick the Story in the first or second piles. If not, they get the Architects
involved. Together, Architects and Developers do Analysis and Design CRC. If
this makes new Architecture, Developers record the User Story as Collaboration
or Sequence Diagrams, and Architects record the architecture as small UML Class
Diagrams (Appendix D). Architects spike new Architecture too. If the
User Story is still a mystery, it’s stuck into the fourth pile.
n
Developers
Don’t Have The Faintest Idea How To Do This. Developers
take the Story back to the Customers and do some business modeling CRC, recording
the results as a Use Case Diagram. If Developers still can’t put this User Story
in one of the other piles, they ask the Customers more questions, or seek out
an expert, or ask the Customers to give it up.
Developers discuss each User Story’s
scope estimate as a group. When all the concerns underlying conflicting estimates
have been exposed, the lowest estimate is adopted.
Conducted as a phase, resolving requirements
this way produces a consistent set of well-quantified User Stories, each of
a granularity suitable for Scheduling, along with just enough modeling products
for a project’s Iterative Development Process to be initiated. And nothing more.
Rather than attempting completeness in an absence of empirical feedback – that
is, rather than just guessing – we use Iterative Development to refine and extend
the understanding of required User Stories through the orderly, regular process
described in the following sections.
Outside of these phases, new requirements
often emerge over the life of the project. As they do, we quantify them as User
Stories. Fixed project timeframes may not permit new User Stories to be included
within an existing Project’s schedule, but because of the formality of our quantification
process this isn’t a decision that developers make. Customers control Story
priorities, and with every Iteration Customers are able to alter these priorities
and thereby influence the placement of User Stories into a Schedule. The actual
process of scheduling User Stories is described in the next section.
Once the Customers are satisfied that all the User Stories
required in the system have been properly quantified, they work with the Developers
to define a Commitment Schedule. The Commitment Schedule is defined in
terms of Iterations, each of which is 3 Real Weeks (15 Real Days) of project
time. The Commitment Schedule specifies the number of Developers and the number
of User Stories that are expected to be delivered in each Iteration. The Commitment
Schedule is initially drawn up before the first Iteration of a Project, but
via the following procedure it can be revisited and altered as often as once
per Iteration – though usually it’s not done nearly that often.
There are two ways to go about drawing up a Commitment
Schedule:
q
Story Driven Commitment:
Business starts putting the User Stories for the project on the table. As each
Story is introduced, Development calculates and announces the Project release
date. This stops when Business is satisfied that the User Stories on the table
make sense as a coherent system.
q
Date Driven Commitment: Business picks a project release date.
Development calculates and announces the cumulative cost of User Stories they
can accomplish between now and the date. Business picks User Stories whose cost
adds up to that number.
Other heuristics are often useful:
q
Priority and Risk First: Development orders the User Stories
in the schedule so:
n
A fully working but sketchy solution is completed immediately
(like in a few weeks)
n
Higher Priority User Stories are moved earlier in the
schedule
n
Riskier User Stories are moved earlier in the schedule
q
Overcommitment Recovery: Development had predicted they could
do 150 User Stories between now and the deadline. Based on Load Factor extrapolations
and other measures of project velocity, they find and immediately announce that
they can only do 120 User Stories in the time that remains. Business selects
the 120 User Stories to retain, deferring the others to a future release. (Highly
Unlikely: Business decides to defer the deadline to get the extra 30 User Stories
done.)
q
Change Priorities: Business changes the Priority of one
or more User Stories. In response, Development may change the order of User
Stories not yet completed.
q
New User Stories: Business comes up with a new Requirement.
With Development they break it down into User Stories. Business defers User
Stories in the Commitment Schedule whose cumulative cost is the cost of the
new User Stories. Development re-evaluates Value and Risk First to insert the
new User Stories into the Schedule.
q
Split User Stories: When resources do not permit
the whole User Story to be done soon enough, Business can split the Story into
two or more. Business assigns Quality and Priority to each, and Development
re-estimates the Scope of each. The results are re-scheduled as per New
User Stories.
q
Re-estimate: Every Iteration, Development may find some User Stories
in the Commitment Schedule that need to be Re-estimated. This could spark an
Overcommitment Recovery, or it may permit New User Stories to be added to the
Schedule.
Resourcing expectations are used to
determine the association between Iterations and User Stories according to the
Load Factor formula described in the section on Estimating Techniques above.
This is a matter of arithmetically determining how many Ideal Days are expected
to be available for each Iteration and then reviewing the delivery dates of
each User Story with the Customers.
As
an Iteration occurs, the User Stories contained by it are further broken down
(by Developers only) into Engineering Tasks as described in the sections on
User Story and Iteration Development Process below.
We use no more process than is necessary. The smallest
units of work that we don’t throw away follow the Engineering Task Development
Process. Stories are decomposed into a number of Engineering tasks that are
developed using the User Story Development Process. Iterations are 3 week periods
in which a number of User Stories are constructed according to the Iteration
Development Process. Iterations exist within Projects that split into four phases
defined by the Project Development Process. Projects contain Iterations which
contain User Stories which contain Engineering Tasks.
It sometimes happens that fire-fights occur simultaneously
with new projects and we are called on to divert some of our resources to fight
the fire and solve it the simplest way that can possibly work. We do this promptly,
but we don’t integrate it into the main line of our development; instead we
define a User Story to correctly re-engineer and integrate the resulting solution
into our main line of development. Our Story Quantification process determines
whether and where these new User Stories fit in a Project’s Commitment Schedule,
and measurements of Load Factor directly represent the impact of the diversion
of resources for management purposes.
High Load Factor and required rigor means the immediate requirements
we can properly address in an Engineering Task are scoped to at least 1 and
no more than 3 Ideal Days. Smaller requirements than this are preferably combined
together by development, even if logically unrelated, until the developers judge
they constitute at least 1 complete Ideal Day of work. Requirements of more
than 3 Ideal Days require more rigor than we can apply in this process and should
be folded into a larger, iterative process. Small requirements that have the
highest priority may be satisfied by throwaway work until we have schedule re-engineering
them as a User Story.
Each Engineering Task involves at least one Pair for at least
one Ideal Day. Each Task will employ at least the following minimal process:
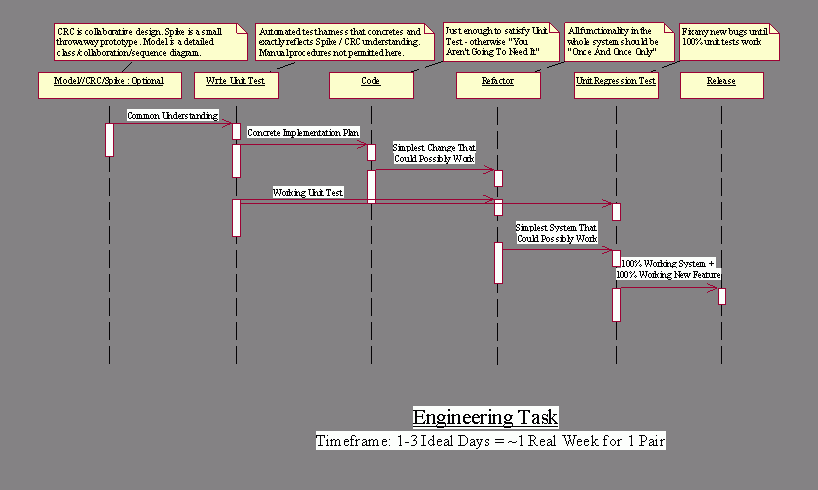
1.
An Engineering Task begins in one
of four ways:
n
A detailed design model has been
prepared previously as part of the User Story Quantification process.
n
A CRC session is held that involves the developers and whatever
Customers are necessary to detail a common understanding.
n
An throwaway prototype (a “Spike”)
is prepared to explore the solution space, or
n
The Customers agree the pair already
has an adequate understanding to deliver a solution.
2.
The pair produces a Scope estimate
for the task in Ideal Days. The aggregate Scope for all a User Story’s Engineering
Tasks might exceed the original estimate for the Story. These discrepancies
will be accounted for by subsequent calculations of Load Factor. It’s important
that the Task estimate is made without pressure by the Pair taking the responsibility.
3.
Before coding anything else, the
Pair codes a unit test that fits into the project’s automated testing framework.
This test is completed before any other code; it faithfully represents a typical
use scenario according to the Pair’s understanding of the specific problem that
the Engineering Task aims to solve.
4.
The pair codes the simplest solution
that could possibly work. They work as fast as possible to build something that
does nothing but satisfy their unit test.
5.
The pair refactors the entire
system to make the whole as simple as it could possibly be. Usually this
refactoring is not dramatic or extensive – but it must be done carefully.
6.
The pair runs the entire unit test
suite to detect and fix any bugs they have introduced by refactoring. They do
this until 100% of the unit tests run fine.
7.
The pair checks in the 100% working
solution plus their new unit test.
This is the simplest process that can maintain system quality.
It doesn’t require a functional test because it doesn’t correspond with a whole
User Story. Nevertheless, it ensures that a small, quick, dirty hack is transformed
into a demonstrably tested solution plus whatever fully tested system changes
are needed to support it. This process leaves no mess for anyone else to waste
time cleaning up afterward.
User Stories each correspond to 1-3 Ideal Weeks. At the start
of each Iteration its scheduled User Stories are broken down by the Architects
and Developers following the procedure described in the Iteration Development
Process section below. A User Story decomposes into a number of Engineering
Tasks, along with one Functional Test.
Story development requires at least the following minimal
process:
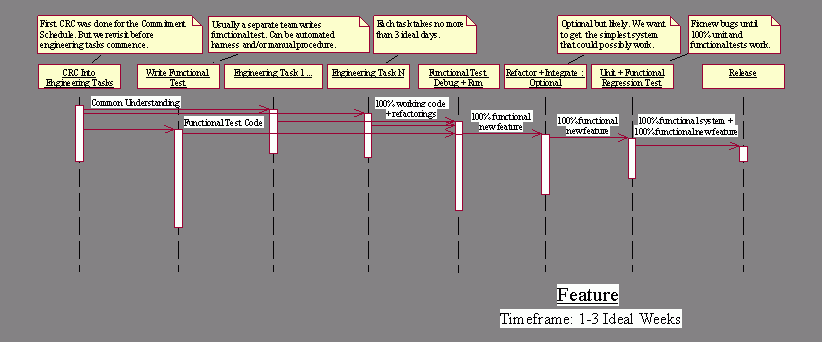
1.
The User Story’s estimation products
are used as a basis for CRC by the developers. If CRC doesn’t easily map onto
the known Architectural elements, the Developers
get the Architects involved; together, Architects and Developers do some Analysis
and Design CRC. If this makes new Architecture, Developers document the User
Story as Collaboration or Sequence Diagrams, and Architects document the new
Architecture as small UML Class Diagrams (See Appendix D). Architects
usually Spike any new Architecture too. The end result is just enough detailed
design product for all Developers to agree they know exactly how to construct
the User Story.
2.
The User Story is broken down into logically self-contained
Engineering Tasks, each of a duration of 1-3 Ideal Days. One extra Engineering
Task is added: the construction of a Functional Test.
3.
The Functional Test is constructed by QA, sometimes
supported by a Developer Pair. A Functional
Test attempts to realistically represent the User Story, Use Case, or Collaboration/Sequence
diagrams that were detailed when its User Story was estimated. Like a Unit Test,
a Functional Test is maintained as part of the automated testing framework.
4.
All Engineering Tasks are implemented in parallel.
5.
When all a User Story’s Engineering Tasks are complete,
the Functional Test is run. Debugging proceeds until the Functional Test succeeds.
6.
Functional testing may optionally
prompt another round of refactoring if Debugging uncovers logical errors or
performance problems.
7.
All available Functional Tests
and Unit Tests are made to run perfectly.
8.
The User Story is released.
Again, this is the simplest process that can maintain deliverable
quality. It requires some extra effort to create a functional test, but otherwise
it’s impossible to be certain that deliverables meet Customer requirements.
By focusing on the context of a User Story, this process coordinates Engineering
Tasks within a tight scope so that Developers can determine what is and what
is not needed. And regression testing ensures that the delivered User Story
doesn’t break the functionality of any other User Story.
An
Iteration is a 3 Real Week period during which we conduct a simple process made
up of elements we’ve already discussed above. The sequence of an Iteration is
as follows:
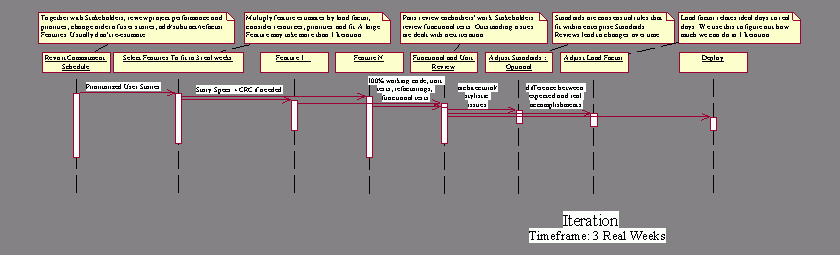
1.
Developers and Customers revisit
the Commitment Schedule to determine which User Stories will be developed this
Iteration.
2.
Developers deliver each User Story
in sequence, never in parallel.
3.
Pairs review each others’ work.
Customers review all Functional Tests. These reviews note implications for the
following Iteration.
4.
Architectural and stylistic concerns
are resolved and this is recorded in the Project Standards document.
5.
Load Factor is calculated for the
next Iteration
Our Project development process closely adheres to RUP phases
and milestones.
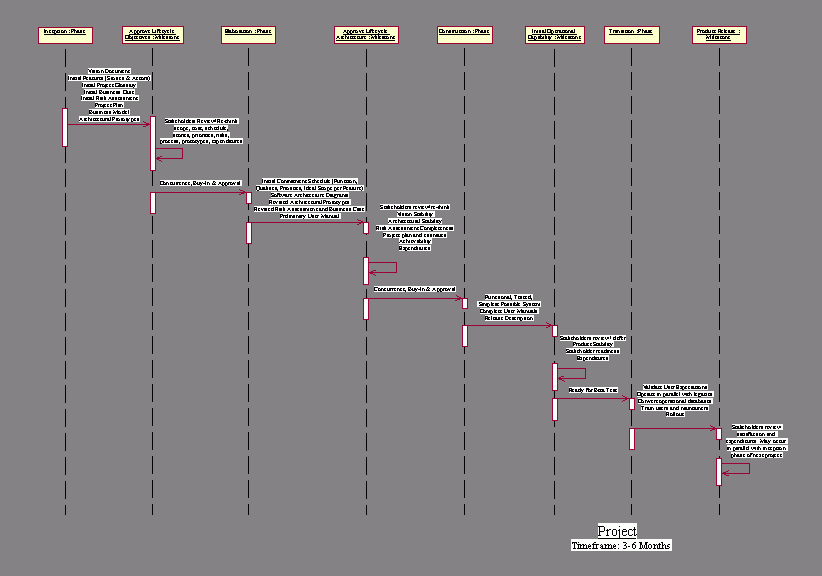
RUP consists
of four phases, each of which is completed by a milestone including a Customer
review of all substantial products. Because we intend to apply this development
process to both large and small projects, we’re careful not to pursue
any of these activities beyond the point that they are actually useful to our
project. We have extended the RUP phases as appropriate to the processes defined
above:
q
Inception: Business modeling
occurs. The business case for the project is established. A Vision document
is constructed to determine boundaries and focus for the gathering of requirements.
Requirements are gathered in terms of User Stories. Logical architecture and
a project glossary are fleshed out. A Risk assessment and Project Plan are prepared.
q
Elaboration: User Stories
that require elaboration and refactoring are transformed via CRC into Use Case
and other UML diagrams. An initial Commitment Schedule is worked out and a preliminary
User Manual is created. Architectural Diagrams and working architectural Spikes
are tested. The business case, risk assessments and other Inception products
are revised.
q
Construction: Iterations
commence as described in the Iteration process above, continuing until the entire
Commitment Schedule is achieved.
q
Transition: Deliverables
are beta-tested and deployed. Deliverables are operated in parallel with legacies.
Operational databases are created/converted. Users are trained and the final
User Manual is revised and delivered.
Architecture activities in the Inception and Elaboration
phases are described in detail in Appendix D.
Between each of these phases there are milestone meetings
where the Customers review all project products and determine whether or not
the project is ready to proceed to the next phase. The project cannot proceed
until each milestone is satisfactorily achieved. These milestones are:
q
Approve Lifecycle Objectives: Occurs at the end of Inception Phase. Customers review and possibly rethink
project scope, costs, schedule, stories, priorities, risks, process, prototypes
and expenditures. They need to reach concurrence about the Project’s objectives,
buy-in to them, and either approve continuing to the Elaboration Phase, continue
the Inception Phase to account for any shortcomings, or cancel the project if
it seems the Vision isn’t worth pursuing after all.
q
Approve Lifecycle Architecture: Occurs at the end of Elaboration Phase. Customers review
and possibly rethink the stability of the Vision document, proposed architecture,
and Project Plan in the light of the Elaboration products. They assess the completeness
of the Commitment Schedule, possibly reprioritizing User Stories in the light
of the Developers’ scope estimates. They assess the project’s expenditures and
achievability, and either approve continuing on to the Construction Phase, continue
the Elaboration Phase to account for any shortcomings, or cancel the project
if it achievability or expenditures don’t meet business criteria.
q
Initial Operational Capability: Occurs at the end of Construction Phase. Customers review
product stability, expenditures, and their readiness for deployment. The project
can’t be cancelled now – most of it has already been delivered – but Customers
may opt to defer deployment or extend the Construction phase before Beta Testing
is allowed to begin.
q
Product Release: Customers review user satisfaction and project expenditures. This review
may occur in parallel with the Inception of a new project.
There are no functional differences between this process
and standard RUP except that we spend much less time in the Elaboration phase
and more time in the Construction Phase as we rely on the iterative completion
of User Stories to complete detailed design work. There’s also more integration
and testing placed in the construction phase than RUP prescribes. The RUP Process
is detailed in great detail in the RUP CD-ROM [16] and at the Rational website
online [17].
Both MSF and XP emphasize the need for teams of peers instead
of hierarchies. The MSF Team Model document describes team structure this way:
“Everybody has
exactly the same job. They have exactly the same job description. And that is
to ship products. Your job is not to write code. Your job is not to test. Your
job is not to write specs. Your job is to ship products. Your role as a developer
or as a tester is secondary […]
To encourage team
members to work closely with each other, they are given broad, interdependent,
and overlapping roles.”
XP Pairing further encourages this identification of developers
with responsibility for the entire deliverable. MSF focuses responsibility for
the Development Process by closely defining six functional roles in each team.
MSF is careful to emphasize that these are not organizational roles; one person
may adopt more than one role, or a role may be shared by more than one person.
It is vital, however, to explicitly account for the all responsibilities of
each role so that they are well covered throughout the development process.
We recognize MSF roles in the processes above as follows:
|
Product Management
|
Meets with and
represents Customers. Structures Business Case & Project Vision. Gathers
and Refines User Stories.
|
|
Program Management
|
Coordinates
and Tracks Commitment Schedule, Scope Estimates, Load Factor, Budget,
Tool and Resource Decisions. Meets with and represents Development. Takes
action if process goes off track.
|
|
Development
|
Prototypes Architecture,
Performs Design, Estimates and Builds Deliverables & Unit Tests.
|
|
Testing
|
Meets with and
represents QA. Designs and Constructs Functional Tests. Graphs Results
and keeps Management clued in.
|
|
User Education
|
Meets with and
represents End Users. Reviews and Influences User Story Design Specs.
Designs, Builds and Tests Reference Cards, Keyboard Templates, User Manuals,
On-Line Help, Wizards, and Courseware. Uses Functional Tests to Validate
Usability.
|
|
Logistics Management
|
Meets with and
represents Operations, Product Support, Help Desk, and other Delivery
Channels. Reviews and Influences User Story Design Specs. Plans and Validates
Deployment. Supports Team Logistical Needs and Trains Operations and Help
Desk Personnel.
|
·
Figure 3 Functional Roles
XP adds a couple of extra Development-specific Functional
Roles to these:
Before a project can begin, a Project Plan must be drawn
up to assign these functional responsibilities to real live team members. Team
members are responsible for the success of their project as a whole, but these
explicit assignments make each team member additionally responsible for ensuring
their particular functions are correctly carried out by the team.
All methodologies use two methods to
partition development time:
n
Phases
order development activities; different activities are conducted in one phase
to those conducted in another. Phased development assumes that all of the prerequisites
for an activity can be more or less completed before that activity is undertaken.
n
Iterations
repeat development activities; the same activities are conducted in every iteration,
but with different inputs. Iterative development assumes that development activities
can be extended and refined in small chunks without losing overall development
context.
All methodologies attempt to structure
and coordinate the same basic activities:
n
planning
to quantify project vision, scope, resources and timeframe
n
requirements
to capture and detail functionality within the planned vision and scope
n
analysis
to synthesize requirements into a detailed specification of the problem domain
n
architecture
to define standard solution techniques, structures and processes appropriate
to the problem domain
n
design
to combine and extend architectural elements to solve specific problems identified
by analysis
n
prototyping
to build a quick and dirty component intended to be thrown
away. When the prototype is as simple as it could possibly be and still work,
we call it a spike
n
construction
to build components and integrate them into deliverables based upon the design
n
unit testing to create small
non-exhaustive tests of component correctness
n
functional
testing to create formal end-to-end tests that validate deliverables
against requirements.
n
performance
testing a variety of functional testing that assures deliverables
meet required performance criteria
n
regression
testing to maintain collections of unit and functional tests
that ensure new deliverables and their components don’t break old deliverables
and their components
n
deployment
to configure and install tested deliverables within a production context
All methodologies divide responsibilities
between a number of different types of personnel:
n
Customers
are business specialists who use, specify, own, and fund a development.
n
Developers
are technologists who design, construct, unit-test, integrate and deploy a development.
n
Architects
are technologists who analyze the business to build generic tools, prototypes,
analyses and high level designs to support the developers.
n
QA
are technologists who construct, automate, maintain and run
functional and regression test harnesses and procedures
n
Infrastructure
are technologists who configure, deploy, install and maintain
the deliverables produced by the developers.
n
Managers
are facilitators who envision, coordinate and maintain the development within
timeframe, resource, quality and scope constraints.
Cowboy Coding
is characterized by:
q
No
organized requirement gathering, project planning or process review.
q
Unmaintainable,
unscalable, inflexible, non-standard architecture.
q
Developer
assignments change frequently, discontinuously, and inconsistently.
q
Project
planning a euphemism for scope-creep.
q
Late,
gross, or missing quantification of requirement quality, resource and timeframe.
q
Development
making business decisions. Business making development decisions.
q
Waterfall
process; no significant developer involvement in planning or estimating.
q
No
unit testing. No regression testing. No automated testing. No systematic functional
testing.
q
Large
disconnects and no organized feedback between development and stakeholders.
Big Brother
is characterized by:
q
Big Design Up Front:
requirements are transformed into analysis and design products without experimental
validation of tool assumptions or iterative feedback from Customers. Bad assumptions
and incorrectly described/scoped requirements are mandated in bulk.
q
Big Models:
to “achieve completeness” and “minimize risk”, analysis and design models are
produced that are larger than developers and stakeholders can easily agree upon.
Time is wasted in Big Meetings attempting to resolve the many inconsistencies
in the Big Models. Big Models age rapidly as business requirements and tool
context change over time. Constructing Big Models confuses and destroys context
present in the small models that make them up.
q
Useless Intermediaries:
intermediary, non-deliverable models are constructed whether or not they are
actually needed by system developers and maintainers. The cost of maintaining
these non-deliverables increases steadily over the project’s life until it becomes
too large for the development to afford
q
Complete Subsystems:
milestones are defined and deliverables deployed by complete subsystem, usually
front-end first. There are initial bouts of stakeholder enthusiasm as functionality
is immediately demonstrated – lights flash and screens format data. Each subsequent
complete subsystem, however, adds little or nothing to this front-end functionality
because required system features need integrated functionality from subsystems
that haven’t been built yet. By the time functional delivery, testing and review
occurs, the project can’t afford the re-engineering required to correct its
integrated deficiencies.
q
All Chiefs:
Developers have little input, responsibility, or visibility in the early parts
of the development process. Managers, architects and consultants are required
for even trivial projects. Estimates become abstract. Methodological jargon
disconnects stakeholders from developers. Objective project considerations are
sidelined by political forces.
q
Analysis Paralysis:
A facile alternative to “All Chiefs”: Developers are tasked to spend months
drawing diagrams, writing specs, and sitting through design reviews. Developers
feel the tasks before them are meaningless, that nothing they produce is tangible,
and that the project is crawling. To “get some real work done”, analysis and
design activities are skimped or prematurely concluded and ad-hoc processes
used to make up the shortfall, resulting in more Cowboy Coding. The remedy that
usually follows is All Chiefs.
“Pitfalls of Object-Oriented
Development” [3] by the Object Systems Group’s Chief Director, Bruce F. Webster,
describes these and many further pathological process variants in great detail.
In order to maintain
the quality of deliverables, all Engineering Tasks Involve two developers working
as a Pair. Ideally, the two actually sit down at the same keyboard, and
we provide office space suitable for that purpose; the actual working method
of each Pair remains a matter for the developers themselves to determine. From
a management perspective it’s only important that the two collaborate and share
responsibility for delivering a whole Engineering Task.
This is not to say we expect each task
to cost twice as much; in fact we expect each task to cost exactly as much as
if it were chopped in two and each developer individually assigned half of it.
We’re not estimating User Stories or Tasks in terms of Pair days above, but
in individual developer days. We lose no efficiency and cost no extra
money by pairing.
If there’s no
cost in pairing, what’s the benefit? Simply, developers don’t work as well in
isolation as they do in Pairs. Two minds are as useful for development perspective
as two eyes are for visual perspective. Pairs of programmers produce better
quality work than do isolated developers. They work smarter and so to better
effect. Several studies have verified that Pair Programming, when conducted
as an open, shared process, dramatically improves productivity and deliverable
quality, The most recent of these is John Nosek’s "The
Case for Collaborative Programming" in the March 1998 CACM [12]. Methodologists
including Lister & DeMarco [13], Cockburn [14], and most notably Cunningham
& Beck [15] strongly support pair programming.
Each member of
a Pair provides feedback, an audience, a source of expertise, a tester, a reviewer,
a sounding board, and a backup for the other. Developer Pairs should be rotated
regularly to spread expertise and ensure collective code ownership. There
are ergonomic and tool support challenges that we need to resolve in order to
pair, but these should be simple to overcome as developers perceive the resulting
benefits.
The chief of these from a Developer standpoint is that
Pair Programming reduces the need for formal code reviews. We make provisions
to conduct informal reviews once per Iteration, but through the use of Pairs
we expect these reviews to be brief and chiefly concerned with revisiting standards
concerns. Over the life of a project we expect even these reviews will become
less involved as project standards mature.
Architecture constructs
a space within which Developers can work comfortably from day to day and a perspective
that elevates their work to a modern professional standard. To achieve this,
Architects employ two overlapping perspectives: Project Architecture and Enterprise
Architecture.
Project Architecture provides tools and techniques for Developers to apply to their Project’s
typical range of User Stories. Project Architecture resolves questions and establishes
contexts necessary for User Story construction to occur:
q
Toolset: Which compilers,
libraries, IDEs, test benches, SCM, Databases, target platforms and so on? Which
existing projects can supply experience and support? Do we apply, integrate,
upgrade or reconfigure existing tools? What other alternatives are there and
how accessible are they?
q
Standards: What corporate,
proprietary, national, or international standards apply? How should we meet
them? How do we resolve conflicts between them?
q
Testing framework: What qualities of our deliverables need to be tested and how? How can we
automate these tests? What optimization techniques do we use and when are they
applied by whom?
q
Generic Components: To what extent can User Stories be constructed from readymade components?
What protocols tie these components together? How should components best be
specialized and combined?
q
Logical Framework: What business entities and concepts are central to our solutions? What
are their behaviors and responsibilities? How do they usually collaborate? What’s
the simplest and most effective way to model them? How will developers specialize
this framework?
q
Data Model: How much data,
what varieties and what sources? What forms of indexing are needed? What scaling
issues are there? What are typical queries and manipulations and how can we
optimize them?
q
Distribution and Concurrency Techniques: What process architecture? What mutual exclusion techniques?
How do we configure and trace components? What mechanism underpins distributed
/ concurrent components? How can we make it all maintainable and transparent?
q
Mapping Between Relational and Object models How do we map a project’s code classes onto its relational
database? [18].
Architecture
is best defined by reference to Patterns. Patterns are proven generic
solutions to well known problems in well defined contexts. Patterns combine
to form self-consistent languages that enable the efficient communication of
architecture. In order to adhere to established industry practices, XP architects
draw on the published standards of Architectural Patterns [19] and Design Patterns
[20], and stay current by following peer forums such as the Portland Pattern
Repository [21] and Pattern Languages of Programming conferences [22]. When
applied with perspective and craft, Patterns make architecture reproducible
and maintainable.
Where practical
we prefer to buy, refine and extend existing architecture than to start it from
scratch. Where we have no choice but to start fresh, we never construct anything
we don’t actually need for a particular project. Nevertheless, we always architect
with an eye to future re-use. As enterprise standards mature we catalog each
Project’s architectural work to contribute to our own domain-specific Pattern
Languages. The activity of documenting, maintaining, refining and propagating
these Patterns is Enterprise Architecture.
1.
http://www.rational.com/uml/resources/documentation/notation/notation7.jtmpl
2.
http://www.sei.cmu.edu/pub/documents/93.reports/pdf/tr24.93.pdf
3.
http://www.amazon.com/exec/obidos/ASIN/1558513973/
4.
http://www.microsoft.com/solutionsframework/
5.
http://c2.com/cgi/wiki?ExtremeProgrammingRoadmap
6.
http://www.rational.com/products/rup/prodinfo/whitepapers/dynamic.jtmpl?doc_key=100420
7.
http://www.rational.com/products/rup/prodinfo/whitepapers/dynamic.jtmpl?doc_key=389
8.
http://www.amazon.com/exec/obidos/ASIN/0201895358/
9.
http://www.rational.com/uml/resources/documentation/notation/index.jtmpl
10. http://www.rational.com/uml/resources/documentation/notation/notation8a.jtmpl
11. http://www.rational.com/uml/resources/documentation/notation/notation5a.jtmpl
12. http://www.acm.org/pubs/articles/journals/cacm/1998-41-3/p105-nosek/p105-nosek.pdf
13. http://www.amazon.com/exec/obidos/ISBN%3D0932633056/
14. http://members.aol.com/acockburn/
15. http://c2.com/cgi/wiki?ProgrammingInPairs
16. http://www.rational.com/products/rup/tryit/rupcd.jtmpl
17. http://www.rational.com/products/rup/index.jtmpl
18. http://members.aol.com/kgb1001001/Chasms.htm
19. http://www.amazon.com/exec/obidos/ASIN/0471958697/
20. http://www.amazon.com/exec/obidos/ASIN/0201633612/
21. http://c2.com/cgi/wiki?StartingPoints
22. http://hillside.net/patterns/conferences/