 具体地说,处理过程如下
具体地说,处理过程如下硬件中断
硬件中断概述
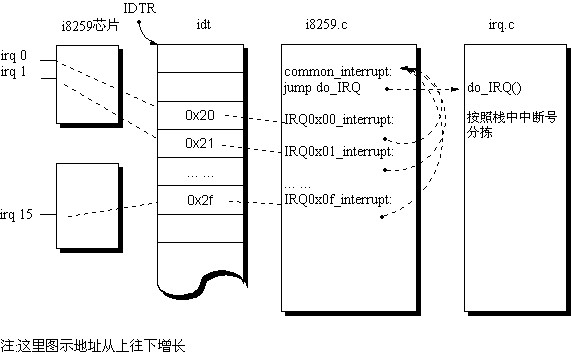
中断可以用下面的流程来表示
:中断产生源
--> 中断向量表 (idt) --> 中断入口 ( 一般简单处理后调用相应的函数) --->do_IRQ--> 后续处理(软中断等工作)如图
:具体地说,处理过程如下
下面一一介绍。
8259
芯片本文主要参考周明德《微型计算机系统原理及应用》和
billpan的相关帖子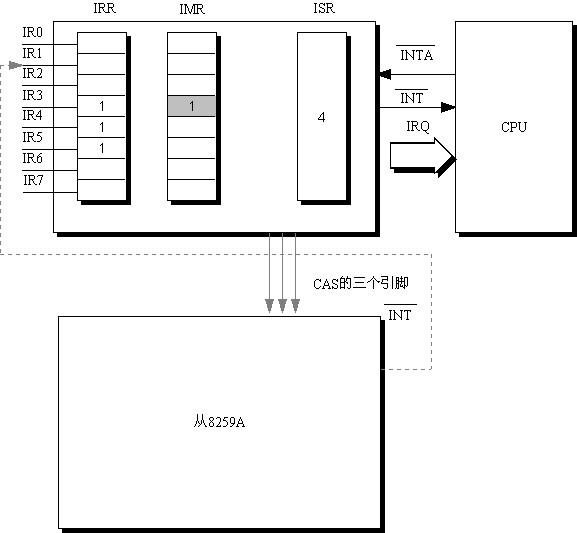
1.
中断产生过程(1)
如果IR引脚上有信号,会使中断请求寄存器(Interrupt Request Register,IRR)相应的位置位,比如图中, IR3, IR4, IR5上有信号,那么IRR的3,4,5为1(2)
如果这些IRR中有一个是允许的,也就是没有被屏蔽,那么就会通过INT向CPU发出中断请求信号。屏蔽是由中断屏蔽寄存器(Interrupt Mask Register,IMR)来控制的,比如图中位3被置1,也就是IRR位3的信号被屏蔽了。在图中,还有4,5的信号没有被屏蔽,所以,会向CPU发出请求信号。(3)
如果CPU处于开中断状态,那么在执行指令的最后一个周期,在INTA上做出回应,并且关中断.(4)8259A
收到回应后,将中断服务寄存器(In-Service Register)置位,而将相应的IRR复位:8259
芯片会比较IRR中的中断的优先级,如上图中,由于IMR中位3处于屏蔽状态,所以实际上只是比较IR4,I5,缺省情况下,IR0最高,依次往下,IR7最低(这种优先级可以被设置),所以上图中,ISR被设置为4.(5)
在CPU发出下一个INTA信号时,8259将中断号送到数据线上,从而能被CPU接收到,这里有个问题:比如在上图中,8259获得的是数4,但是CPU需要的是中断号(并不为4),从而可以到idt找相应的向量。所以有一个从ISR的信号到中断号的转换。在Linux的设置中,4对应的中断号是0x24.(6)
如果8259处于自动结束中断(Automatic End of Interrupt AEOI)状态,那么在刚才那个INTA信号结束前,8259的ISR复位(也就是清0),如果不处于这个状态,那么直到CPU发出EOI指令,它才会使得ISR复位。
2.
一些相关专题(1)
从8259在
x86单CPU的机器上采用两个8259芯片,主芯片如上图所示,x86模式规定,从8259将它的INT脚与主8259的IR2相连,这样,如果从8259芯片的引脚IR8-IR15上有中断,那么会在INT上产生信号,主8259在IR2上产生了一个硬件信号,当它如上面的步骤处理后将IR2的中断传送给CPU,收到应答后,会通过CAS通知从8259芯片,从8259芯片将IRQ中断号送到数据线上,从而被CPU接收。由此,我猜测它产生的所有中断在主
8259上优先级为2,不知道对不对。(2)
关于屏蔽从上面可以看出,屏蔽有两种方法,一种作用于
CPU, 通过清除IF标记,使得CPU不去响应8259在INT上的请求。也就是所谓关中断。另一种方法是,作用于
8259,通过给它指令设置IMR,使得相应的IRR不参与ISR(见上面的(4)),被称为禁止(disable),反之,被称为允许(enable).每次设置
IMR只需要对端口0x21(主)或0xA1(从)输出一个字节即可,字节每位对应于IMR每位,例如:outb(cached_21,0x21);
为了统一处理
16个中断,Linux用一个16位cached_irq_mask变量来记录这16个中断的屏蔽情况:static unsigned int cached_irq_mask = 0xffff;
为了分别对应于主从芯片的
8位IMR,将这16位cached_irq_mask分成两个8位的变量:#define __byte(x,y) (((unsigned char *)&(y))[x])
#define cached_21 (__byte(0,cached_irq_mask))
#define cached_A1 (__byte(1,cached_irq_mask))
在禁用某个
irq的时候,调用下面的函数:void disable_8259A_irq(unsigned int irq){
unsigned int mask = 1 << irq; unsigned long flags;
cached_irq_mask |= mask;/*--
对这16位变量设置 */if (irq & 8)/*--
看是对主8259设置还是对从芯片设置 */ outb(cached_A1,0xA1);/*-- 对从8259芯片设置 */else
outb(cached_21,0x21);/*--
}
(3)
关于中断号的输出8259
在ISR里保存的只是irq的ID,但是它告诉CPU的是中断向量ID,比如ISR保存时钟中断的ID 0,但是在通知CPU却是中断号0x20.因此需要建立一个映射。在8259芯片产生的IRQ号必须是连续的,也就是如果irq0对应的是中断向量0x20,那么irq1对应的就是0x21,...在
i8259.c/init_8259A()中,进行设置:outb_p(0x11, 0x20);
/* ICW1: select 8259A-1 init */outb_p(0x20 + 0, 0x21);
/* ICW2: 8259A-1 IR0-7 mapped to 0x20-0x27 */outb_p(0x04, 0x21);
/* 8259A-1 (the master) has a slave on IR2 */if (auto_eoi)
outb_p(0x03, 0x21);
/* master does Auto EOI */else
outb_p(0x01, 0x21);
/* master expects normal EOI */outb_p(0x11, 0xA0);
/* ICW1: select 8259A-2 init */outb_p(0x20 + 8, 0xA1);
/* ICW2: 8259A-2 IR0-7 mapped to 0x28-0x2f */outb_p(0x02, 0xA1);
/* 8259A-2 is a slave on master's IR2 */outb_p(0x01, 0xA1);
/* (slave's support for AEOI in flat mode is to be investigated) */这样,在
IDT的向量0x20-0x2f可以分别填入相应的中断处理函数的地址了。向量表设置
注
:图片均取自i386开发者手册.i386
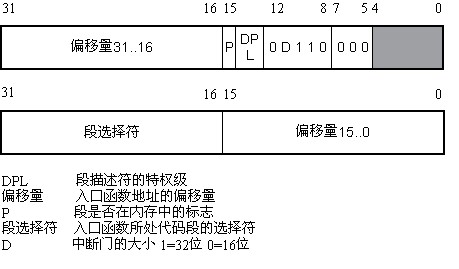
中断门描述符描述符如图
: 段选择符和偏移量决定了中断处理函数的入口地址,如下图。
段选择符和偏移量决定了中断处理函数的入口地址,如下图。
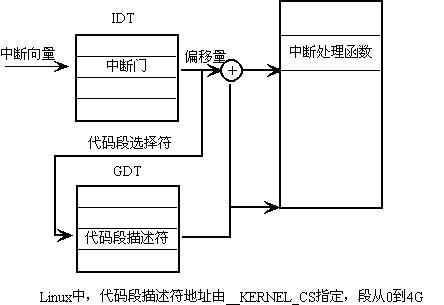
在这里段选择符指向内核中唯一的一个代码段描述符的地址
__KERNEL_CS(=0x10),而这个描述符定义的段为0到4G:---------------------------------------------------------------------------------
ENTRY(gdt_table) .quad 0x0000000000000000 /* NULL descriptor */
.quad 0x0000000000000000 /* not used */
.quad 0x00cf9a000000ffff /* 0x10 kernel 4GB code at 0x00000000 */
... ...
---------------------------------------------------------------------------------
而偏移量就成了绝对的偏移量了,在
IDT的描述符中被拆成了两部分,分别放在头和尾。P
标志着这个代码段是否在内存中,本来是i386提供的类似缺页的机制,在Linux中这个已经不用了,都设成1(当然内核代码是永驻内存的,但即使不在内存,推测linux也只会用缺页的标志)。DPL
在这里是0级(特权级)0D110
中,D为1,表明是32位程序(这个细节见i386开发手册).110是中断门的标识,其它101是任务门的标识, 111是陷阱(trap)门标识。
Linux
对中断门的设置于是在
Linux中对硬件中断的中断门的设置为:init_IRQ(void)
---------------------------------------------------------
for (i = 0; i < NR_IRQS; i++) {
int vector = FIRST_EXTERNAL_VECTOR + i;
if (vector != SYSCALL_VECTOR)
set_intr_gate(vector, interrupt[ i]);
}
----------------------------------------------------------
其中,
FIRST_EXTERNAL_VECTOR=0x20,恰好为8259芯片的IR0的中断门(见8259部分),也就是时钟中断的中断门),interrupt[ i]为相应处理函数的入口地址NR_IRQS=224, =256(IDT
的向量总数)-32(CPU保留的中断的个数),在这里设置了所有可设置的向量。SYSCALL_VECTOR=0x80,
在这里意思是避开系统调用这个向量。而
set_intr_gate的定义是这样的:----------------------------------------------------
void set_intr_gate(unsigned int n, void *addr){
_set_gate(idt_table+n,14,0,addr);
}
----------------------------------------------------
其中,需要解释的是
:14是标识指明这个是中断门,注意上面的0D110=01110=14;另外,0指明的是DPL.中断入口
以
8259的16个中断为例:通过宏
BUILD_16_IRQS(0x0), BI(x,y),以及#define BUILD_IRQ(nr) \
asmlinkage void IRQ_NAME(nr); \
__asm__( \
"\n"__ALIGN_STR"\n" \
SYMBOL_NAME_STR(IRQ) #nr "_interrupt:\n\t" \
"pushl $"#nr"-256\n\t" \
"jmp common_interrupt");
得到的
16个中断处理函数为:IRQ0x00_interrupt:
push $0x00 - 256
jump common_interrupt
IRQ0x00_interrupt:
push $0x01 - 256
jump common_interrupt
... ...
IRQ0x0f_interrupt:
push $0x0f - 256
jump common_interrupt
这些处理函数简单的把中断号
-256(为什么-256,也许是避免和内部中断的中断号有冲突)压到栈中,然后跳到common_interrupt其中
common_interrupt是由宏BUILD_COMMON_IRQ()展开:
#define BUILD_COMMON_IRQ() \
asmlinkage void call_do_IRQ(void); \
__asm__( \
"\n" __ALIGN_STR"\n" \
"common_interrupt:\n\t" \
SAVE_ALL \
"pushl $ret_from_intr\n\t" \
SYMBOL_NAME_STR(call_do_IRQ)":\n\t" \
"jmp "SYMBOL_NAME_STR(do_IRQ));
.align 4,0x90common_interrupt:
SAVE_ALL
展开的保护现场部分push $ret_from_intrcall
do_IRQ:
jump do_IRQ;
从上面可以看出,这
16个的中断处理函数不过是把中断号-256压入栈中,然后保护现场,最后调用do_IRQ .在common_interrupt中,为了使do_IRQ返回到entry.S的ret_from_intr标号,所以采用的是压入返回点ret_from_intr,用jump来模拟一个从ret_from_intr上面对do_IRQ的一个调用。
和
IDT的衔接为了便于
IDT的设置,在数组interrupt中填入所有中断处理函数的地址:void (*interrupt[NR_IRQS])(void) = {
IRQ0x00_interrupt,
IRQ0x01_interrupt,
... ...
}
在中断门的设置中,可以看到是如何利用这个数组的。
硬件中断处理函数
do_IRQdo_IRQ
的相关对象在
do_IRQ中,一个中断主要由三个对象来完成,如图: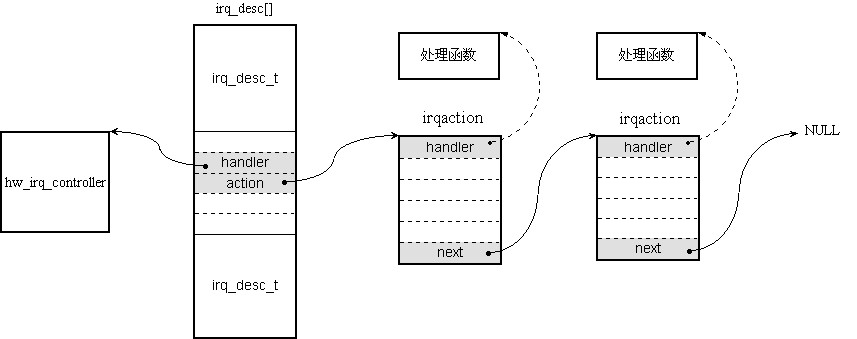
其中
, irq_desc_t对象构成的irq_desc[]数组元素分别对应了224个硬件中断(idt一共256项,cpu自己前保留了32项,256-32=224,当然这里面有些项是不用的,比如x80是系统调用).当发生中断时,函数
do_IRQ就会在irq_desc[]相应的项中提取各种信息来完成对中断的处理。irq_desc
有一个字段handler指向发出这个中断的设备的处理对象hw_irq_controller,比如在单CPU,这个对象一般就是处理芯片8259的对象。为什么要指向这个对象呢?因为当发生中断的时候,内核需要对相应的中断进行一些处理,比如屏蔽这个中断等。这个时候需要对中断设备(比如8259芯片)进行操作,于是可以通过这个指针指向的对象进行操作。irq_desc
还有一个字段action指向对象irqaction,后者是产生中断的设备的处理对象,其中的handler就是处理函数。由于一个中断可以由多个设备发出,Linux内核采用轮询的方式,将所有产生这个中断的设备的处理对象连成一个链表,一个一个执行。例如,硬盘
1,硬盘2都产生中断IRQx,在do_IRQ中首先找到irq_desc[x],通过字段handler对产生中断IRQx的设备进行处理(对8259而言,就是屏蔽以后的中断IRQx),然后通过action先后运行硬盘1和硬盘2的处理函数。
hw_irq_controller
hw_irq_controller
有多种:1.
在一般单cpu的机器上,通常采用两个8259芯片,因此hw_irq_controller指的就是i8259A_irq_type2.
在多CPU的机器上,采用APIC子系统来处理芯片,APIC有3个部分组成,一个是I/O APIC模块,其作用可比做8259芯片,但是它发出的中断信号会通过 APIC总线送到其中一个(或几个)CPU中的Local APIC模块,因此,它还起一个路由的作用;它可以接收16个中断。中断可以采取两种方式,电平触发和边沿触发,相应的,
I/O APIC模块的hw_irq_controller就有两种:ioapic_level_irq_type
ioapic_edge_irq_type
(
这里指的是intel的APIC,还有其它公司研制的APIC,我没有研究过)3. Local APIC
自己也能单独处理一些直接对CPU产生的中断,例如时钟中断(这和没有使用Local APIC模块的CPU不同,它们接收的时钟中断来自外围的时钟芯片),因此,它也有自己的 hw_irq_controller:lapic_irq_type
struct hw_interrupt_type {
const char * typename;
unsigned int (*startup)(unsigned int irq);
void (*shutdown)(unsigned int irq);
void (*enable)(unsigned int irq);
void (*disable)(unsigned int irq);
void (*ack)(unsigned int irq);
void (*end)(unsigned int irq);
void (*set_affinity)(unsigned int irq, unsigned long mask);
}
;typedef struct hw_interrupt_type hw_irq_controller;
startup
shutdown
反之,使得芯片不再接收中断enable
设某个引脚可以接收中断,也就是取消屏蔽disable
屏蔽某个引脚,例如,如果屏蔽0那么时钟中断就不再发生ack
end
在CPU处理完某个引脚产生的中断后,对中断芯片(模块)的操作。irqaction
将一个硬件处理函数挂到相应的处理队列上去
(当然首先要生成一个irqaction结构):-----------------------------------------------------
int request_irq(unsigned int irq,
void (*handler)(int, void *, struct pt_regs *),
unsigned long irqflags,
const char * devname,
void *dev_id)
-----------------------------------------------------
参数说明在源文件里说得非常清楚。
handler
是硬件处理函数,在下面的代码中可以看得很清楚:---------------------------------------------
do {
status |= action->flags;
action->handler(irq, action->dev_id, regs);
action = action->next;
} while (action);
---------------------------------------------
第二个参数就是
action的dev_id,这个参数非常灵活,可以派各种用处。而且要保证的是,这个dev_id在这个处理链中是唯一的,否则删除会遇到麻烦。第三个参数是在
entry.S中压入的各个积存器的值。它的大致流程是
:1.
在slab中分配一个irqaction,填上必需的数据以下在函数
setup_irq中。2.
找到它的irq对应的结构irq_desc3.
看它是否想对随机数做贡献4.
看这个结构上是否已经挂了其它处理函数了,如果有,则必须确保它本身和这个队列上所有的处理函数都是可共享的(由于传递性,只需判断一个就可以了)5.
挂到队列最后6.
如果这个irq_desc只有它一个irqaction,那么还要进行一些初始化工作7
在proc/下面登记 register_irq_proc(irq)(这个我不太明白)将一个处理函数取下
:void free_irq(unsigned int irq, void *dev_id)
首先在队列里找到这个处理函数
(严格的说是irqaction),主要靠dev_id来匹配,这时dev_id的唯一性就比较重要了。将它从队列里剔除。
如果这个中断号没有处理函数了,那么禁止这个中断号上再产生中断
:if (!desc->action) {
desc->status |= IRQ_DISABLED;
desc->handler->shutdown(irq);
}
如果其它
CPU在运行这个处理函数,要等到它运行完了,才释放它:#ifdef CONFIG_SMP
/* Wait to make sure it's not being used on another CPU */
while (desc->status & IRQ_INPROGRESS)
barrier();
#endif
kfree(action);
do_IRQ
asmlinkage unsigned int do_IRQ(struct pt_regs regs)
1.
首先取中断号,并且获取对应的irq_desc:int irq = regs.orig_eax & 0xff; /* high bits used in ret_from_ code */
int cpu = smp_processor_id();
irq_desc_t *desc = irq_desc + irq;
2.
对中断芯片(模块)应答:desc->handler->ack(irq);
3
.修改它的状态(注:这些状态我觉得只有在SMP下才有意义):status = desc->status & ~(IRQ_REPLAY | IRQ_WAITING);
status |= IRQ_PENDING; /* we _want_ to handle it */
IRQ_REPLAY
是指如果被禁止的中断号上又产生了中断,这个中断是不会被处理的,当这个中断号被允许产生中断时,会将这个未被处理的中断转为IRQ_REPLAY。IRQ_WAITING
探测用,探测时,会将所有没有挂处理函数的中断号上设置IRQ_WAITING,如果这个中断号上有中断产生,就把这个状态去掉,因此,我们就可以知道哪些中断引脚上产生过中断了。IRQ_PENDING
, IRQ_INPROGRESS是为了确保:具体的说
,当内核在运行某个中断号对应的处理程序(链)时,状态会设置成IRQ_INPROGRESS。如果在这期间,同一个中断号上又产生了中断,并且传给CPU,那么当内核打算再次运行这个中断号对应的处理程序(链)时,发现已经有一个实例在运行了,就将这下一个中断标注为IRQ_PENDING, 然后返回。这个已在运行的实例结束的时候,会查看是否期间有同一中断发生了,是则再次执行一遍。这些状态的操作不是在什么情况下都必须的,事实上,一个
CPU,用8259芯片,无论即使是开中断,也不会发生中断重入的情况,因为在这期间,内核把同一中断屏蔽掉了。多个
CPU比较复杂,因为CPU由Local APIC,每个都有自己的中断,但是它们可能调用同一个函数,比如时钟中断,每个CPU都可能产生,它们都会调用时钟中断处理函数。从
I/O APIC传过来的中断,如果是电平触发,也不会,因为在结束发出EOI前,这个引脚上是不接收中断信号。如果是边沿触发,要么是开中断,要么I/O APIC选择不同的CPU,在这两种情况下,会有重入的可能。/*
* If the IRQ is disabled for whatever reason, we cannot
* use the action we have.
*/
action = NULL;
if (!(status & (IRQ_DISABLED | IRQ_INPROGRESS))) {
action = desc->action;
status &= ~IRQ_PENDING; /* we commit to handling */
status |= IRQ_INPROGRESS; /* we are handling it *//*
进入执行状态*/}
desc->status = status;
/*
* If there is no IRQ handler or it was disabled, exit early.
Since we set PENDING, if another processor is handling
a different instance of this same irq, the other processor
will take care of it.
*/
if (!action)
goto out;/*
要么该中断没有处理函数;要么被禁止运行(IRQ_DISABLE);要么有一个实例已经在运行了*//*
* Edge triggered interrupts need to remember
* pending events.
* This applies to any hw interrupts that allow a second
* instance of the same irq to arrive while we are in do_IRQ
* or in the handler. But the code here only handles the _second_
* instance of the irq, not the third or fourth. So it is mostly
* useful for irq hardware that does not mask cleanly in an
* SMP environment.
*/
for (;;) {
spin_unlock(&desc->lock);
handle_IRQ_event(irq, ®s, action);/*
执行函数链*/spin_lock(&desc->lock);
if (!(desc->status & IRQ_PENDING))/*
发现期间有中断,就再次执行*/break;
desc->status &= ~IRQ_PENDING;
}
desc->status &= ~IRQ_INPROGRESS;/*
退出执行状态*/out:
/*
* The ->end() handler has to deal with interrupts which got
* disabled while the handler was running.
*/
desc->handler->end(irq);/*
给中断芯片一个结束的操作,一般是允许再次接收中断*/spin_unlock(&desc->lock);
if (softirq_active(cpu) & softirq_mask(cpu))
do_softirq();/*
执行软中断*/return 1;
}
软中断
softirqsoftirq
简介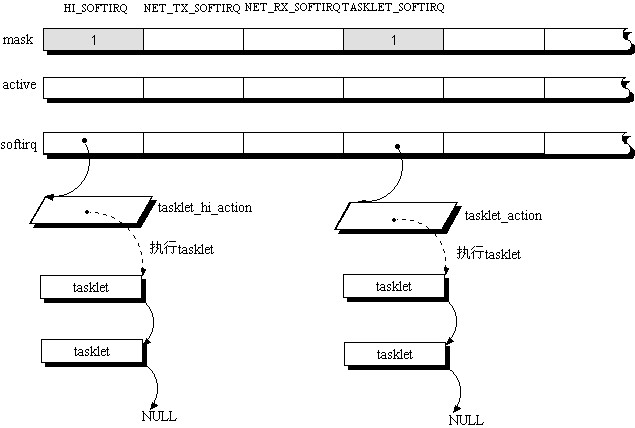 提出
提出
Linux
内核中一共可以有32个softirq,每个softirq实际上就是指向一个函数。当内核执行softirq(do_softirq),就对这32个softirq进行轮询:(1)
是否该softirq被定义了,并且允许被执行?(2)
是否激活了(也就是以前有中断要求它执行)?如果得到肯定的答复,那么就执行这个
softirq指向的函数。值得一提的是,无论有多少个
CPU,内核一共只有32个公共的softirq,但是每个CPU可以执行不同的softirq,可以禁止/起用不同的softirq,可以激活不同的softirq,因此,可以说,所有CPU有相同的例程,但是每个
CPU却有自己完全独立的实例。对
(1)的判断是通过考察irq_stat[ cpu ].mask相应的位得到的。这里面的cpu指的是当前指令所在的cpu.在一开始,softirq被定义时,所有的cpu的掩码mask都是一样的。但是在实际运行中,每个cpu上运行的程序可以根据自己的需要调整。对
(2)的判断是通过考察irq_stat[ cpu ].active相应的位得到的.虽然原则上可以任意定义每个
softirq的函数,Linux内核为了进一步加强延迟中断功能,提出了tasklet的机制。tasklet实际上也就是一个函数。在第0个softirq的处理函数tasklet_hi_action中,我们可以看到,当执行这个函数的时候,会依次执行一个链表上所有的tasklet.我们大致上可以把
softirq的机制概括成:内核依次对
32个softirq轮询,如果遇到一个可以执行并且需要的softirq,就执行对应的函数,这些函数有可能又会执行一个函数队列。当执行完这个函数队列后,才会继续询问下一个softirq对应的函数。
挂上一个软中断
void open_softirq(int nr, void (*action)(struct softirq_action*), void *data)
{
unsigned long flags;
int i;
spin_lock_irqsave(&softirq_mask_lock, flags);
softirq_vec[nr].data = data;
softirq_vec[nr].action = action;
for (i=0; i<NR_CPUS; i++)
softirq_mask(i) |= (1<<nr);
spin_unlock_irqrestore(&softirq_mask_lock, flags);
}
其中对每个
CPU的softirq_mask都标注一下,表明这个softirq被定义了。tasklet
在这个
32个softirq中,有的softirq的函数会依次执行一个队列中的tasklet,如第一帖中图所示。tasklet
其实就是一个函数。它的结构如下:struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
next
用于将tasklet串成一个队列state
表示一些状态,后面详细讨论count
func
即为所要执行的函数。data
由于可能多个tasklet调用公用函数,因此用data可以区分不同tasklet.如何将一个
tasklet挂上首先要初始化一个tasklet,填上相应的参数
void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data)
{
t->func = func;
t->data = data;
t->state = 0;
atomic_set(&t->count, 0);
}
然后调用
schedule函数,注意,下面的函数仅仅是将这个tasklet挂到 TASKLET_SOFTIRQ对应的软中断所执行的tasklet队列上去, 事实上,还有其它的软中断,比如HI_SOFTIRQ,会执行其它的tasklet队列,如果要挂上,那么就要调用tasklet_hi_schedule(). 如果你自己写的softirq执行一个tasklet队列,那么你需要自己写类似下面的函数。static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) {
int cpu = smp_processor_id();
unsigned long flags;
local_irq_save(flags);
/**/ t->next = tasklet_vec[cpu].list;
/**/ tasklet_vec[cpu].list = t;
__cpu_raise_softirq(cpu, TASKLET_SOFTIRQ);
local_irq_restore(flags);
}
}
这个函数中
/**/标注的句子用来挂接上tasklet,__cpu_raise_softirq
用来激活TASKLET_SOFTIRQ,这样,下次执行do_softirq就会执行这个TASKLET_SOFTIRQ软中断了__cpu_raise_softirq
定义如下:static inline void __cpu_raise_softirq(int cpu, int nr)
{
softirq_active(cpu) |= (1<<nr);
}
tasklet
的运行方式我们以
tasklet_action为例,来说明tasklet运行机制。事实上,还有一个函数tasklet_hi_action同样也运行tasklet队列。首先值得注意的是,我们前面提到过,所有的
cpu共用32个softirq,但是同一个softirq在不同的cpu上执行的数据是独立的,基于这个原则,tasklet_vec对每个cpu都有一个,每个cpu都运行自己的tasklet队列。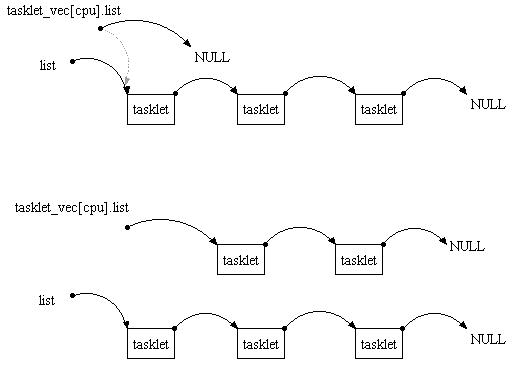
当执行一个
tasklet队列时,内核将这个队列摘下来,以list为队列头,然后从list的下一个开始依次执行。这样做达到什么效果呢?在执行这个队列时,这个队列的结构是静止的,如果在运行期间,有中断产生,并且往这个队列里添加tasklet的话,将填加到tasklet_vec[cpu].list中, 注意这个时候,这个队列里的任何tasklet都不会被执行,被执行的是list接管的队列。见
/*1*//*2/之间的代码。事实上,在一个队列上同时添加和运行也是可行的,没这个简洁。-----------------------------------------------------------------
static void tasklet_action(struct softirq_action *a)
{
int cpu = smp_processor_id();
struct tasklet_struct *list;
/*1*/ local_irq_disable();
list = tasklet_vec[cpu].list;
tasklet_vec[cpu].list = NULL;
/*2*/ local_irq_enable();
while (list != NULL) {
struct tasklet_struct *t = list;
list = list->next;
/*3*/ if (tasklet_trylock(t)) {
if (atomic_read(&t->count) == 0) {
clear_bit(TASKLET_STATE_SCHED, &t->state);
t->func(t->data);
/*
* talklet_trylock() uses test_and_set_bit that imply
* an mb when it returns zero, thus we need the explicit
* mb only here: while closing the critical section.
*/
#ifdef CONFIG_SMP
/*?*/ smp_mb__before_clear_bit();
#endif
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
/*4*/ local_irq_disable();
t->next = tasklet_vec[cpu].list;
tasklet_vec[cpu].list = t;
__cpu_raise_softirq(cpu, TASKLET_SOFTIRQ);
/*5*/ local_irq_enable();
}
}
-------------------------------------------------------------
/*3*/
看其它cpu是否还有同一个tasklet在执行,如果有的话,就首先将这个tasklet重新放到tasklet_vec[cpu].list指向的预备队列(见/*4*/~/*5*/),而后跳过这个tasklet.这也就说明了
tasklet是不可重入的,以防止两个相同的tasket访问同样的变量而产生竞争条件(race condition)tasklet
的状态在
tasklet_struct中有一个属性state,用来表示tasklet的状态:tasklet
的状态有3个:1.
当tasklet被挂到队列上,还没有执行的时候,是 TASKLET_STATE_SCHED2.
当tasklet开始要被执行的时候,是 TASKLET_STATE_RUN其它时候,则没有这两个位的设置
其实还有另一对状态,禁止或允许,
tasklet_struct中用count表示,用下面的函数操作
-----------------------------------------------------
static inline void tasklet_disable_nosync(struct tasklet_struct *t)
{
atomic_inc(&t->count);
}
static inline void tasklet_disable(struct tasklet_struct *t)
{
tasklet_disable_nosync(t);
tasklet_unlock_wait(t);
}
static inline void tasklet_enable(struct tasklet_struct *t)
{
atomic_dec(&t->count);
}
-------------------------------------------------------
下面来验证
1,2这两个状态:当被挂上队列时
:首先要测试它是否已经被别的
cpu挂上了,如果已经在别的cpu挂上了,则不再将它挂上,否则设置状态为TASKLET_STATE_SCHED
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) {
... ...
}
为什么要这样做
?试想,如果一个tasklet已经挂在一队列上,内核将沿着这个队列一个个执行,现在如果又被挂到另一个队列上,那么这个tasklet的指针指向另一个队列,内核就会沿着它走到错误的队列中去了。
tasklet
开始执行时:在
tasklet_action中:------------------------------------------------------------
while (list != NULL) {
struct tasklet_struct *t = list;
/*0*/ list = list->next;
/*1*/ if (tasklet_trylock(t)) {
/*2*/ if (atomic_read(&t->count) == 0) {
/*3*/ clear_bit(TASKLET_STATE_SCHED, &t->state);
t->func(t->data);
/*
* talklet_trylock() uses test_and_set_bit that imply
* an mb when it returns zero, thus we need the explicit
* mb only here: while closing the critical section.
*/
#ifdef CONFIG_SMP
smp_mb__before_clear_bit();
#endif
/*4*/ tasklet_unlock(t);
continue;
}
---------------------------------------------------------------
1
看是否是别的cpu上这个tasklet已经是 TASKLET_STATE_RUN了,如果是就跳过这个tasklet2
看这个tasklet是否被允许运行?3
清除TASKLET_STATE_SCHED,为什么现在清除,它不是还没有从队列上摘下来吗?事实上,它的指针已经不再需要的,它的下一个tasklet已经被list记录了(/*0*/)。这样,如果其它cpu把它挂到其它的队列上去一点影响都没有。4
清除TASKLET_STATE_RUN标志1
和4确保了在所有cpu上,不可能运行同一个tasklet,这样在一定程度上确保了tasklet对数据操作是安全的,但是不要忘了,多个tasklet可能指向同一个函数,所以仍然会发生竞争条件。可能会有疑问
:假设cpu 1上已经有tasklet 1挂在队列上了,cpu2应该根本挂不上同一个tasklet 1,怎么会有tasklet 1和它发生重入的情况呢?答案就在
/*3*/上,当cpu 1的tasklet 1已经不是TASKLET_STATE_SCHED,而它还在运行,这时cpu2完全有可能挂上同一个tasklet 1,而且使得它试图运行,这时/*1*/的判断就起作用了。软中断的重入
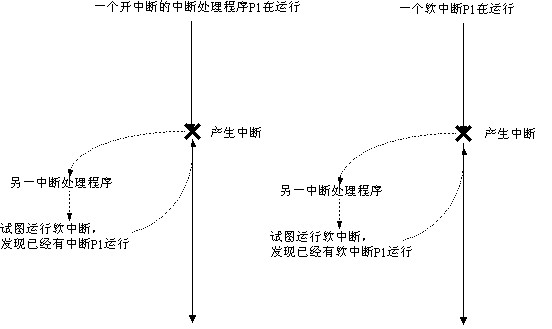
如图,一般情况下,在硬件中断处理程序后都会试图调用do_softirq执行软中断,但是如果发现现在已经有中断在运行,或者已经有软中断在运行,则
不再运行自己调用的中断。也就是说,软中断是不能进入硬件中断部分的
,并且软中断在一个cpu上是不可重入的,或者说是串行化的(serialize)其目的是避免访问同样的变量导致竞争条件的出现。在开中断的中断处理程序中不允许调用软中断可能是希望这个中断处理程序尽快结束。
这是由
do_softirq中的if (in_interrupt())
return;
保证的
.其中,
#define in_interrupt() ({ int __cpu = smp_processor_id(); \
(local_irq_count(__cpu) + local_bh_count(__cpu) != 0); })
前者
local_irq_count(_cpu):当进入硬件中断处理程序时,
handle_IRQ_event中的irq_enter(cpu, irq)会将它加1,表明又进入一个硬件中断退出则调用
irq_exit(cpu, irq)后者
local_bh_count(__cpu) :当进入软中断处理程序时,
do_softirq中的local_bh_disable()会将它加1,表明处于软中断中local_bh_disable();
一个例子:
当内核正在执行处理定时器的软中断时,这期间可能会发生多个时钟中断,这些时钟中断的处理程序都试图再次运行处理定时器的软中断,但是由于
已经有个软中断在运行了,于是就放弃返回。
软中断调用时机
最直接的调用:
当硬中断执行完后,迅速调用
do_softirq来执行软中断(见下面的代码),这样,被硬中断标注的软中断能得以迅速执行。当然,不是每次调用都成功的,见前面关于重入的帖子。-----------------------------------------------------
asmlinkage unsigned int do_IRQ(struct pt_regs regs)
{
... ...
if (softirq_active(cpu) & softirq_mask(cpu))
do_softirq();
}
-----------------------------------------------------
还有,不是每个被标注的软中断都能在这次陷入内核的部分中完成,可能会延迟到下次中断。
其它地方的调用
:在
entry.S中有一个调用点:handle_softirq:
call SYMBOL_NAME(do_softirq)
jmp ret_from_intr
有两处调用它,一处是当系统调用处理完后
:ENTRY(ret_from_sys_call)
#ifdef CONFIG_SMP
movl processor(%ebx),%eax
shll $CONFIG_X86_L1_CACHE_SHIFT,%eax
movl SYMBOL_NAME(irq_stat)(,%eax),%ecx # softirq_active
testl SYMBOL_NAME(irq_stat)+4(,%eax),%ecx # softirq_mask
#else
movl SYMBOL_NAME(irq_stat),%ecx # softirq_active
testl SYMBOL_NAME(irq_stat)+4,%ecx # softirq_mask
#endif
jne handle_softirq
一处是当异常处理完后:
ret_from_exception:
#ifdef CONFIG_SMP
GET_CURRENT(%ebx)
movl processor(%ebx),%eax
shll $CONFIG_X86_L1_CACHE_SHIFT,%eax
movl SYMBOL_NAME(irq_stat)(,%eax),%ecx # softirq_active
testl SYMBOL_NAME(irq_stat)+4(,%eax),%ecx # softirq_mask
#else
movl SYMBOL_NAME(irq_stat),%ecx # softirq_active
testl SYMBOL_NAME(irq_stat)+4,%ecx # softirq_mask
#endif
jne handle_softirq
注意其中的
irq_stat, irq_stat +4 对应的就是字段 active和mask既然我们每次调用完硬中断后都马上调用软中断,为什么还要在这里调用呢
?原因可能都多方面的
:(1)
在系统调用或者异常处理中同样可以标注软中断,这样它们在返回前就能得以迅速执行(2)
前面提到,有些软中断要延迟到下次陷入内核才能执行,系统调用和异常都陷入内核,所以可以尽早的把软中断处理掉(3)
如果在异常或者系统调用中发生中断,那么前面提到,可能还会有一些软中断没有处理,在这两个地方做一个补救工作,尽量避免到下次陷入内核才处理这些软中断。另外,在切换前也调用。
bottom half
2.2.x中的bottom half :
2.2.x版本中的bottom half就相当于2.4.1中的softirq.它的问题在于只有32个,如果要扩充的话,需要task 队列(这里task不是进程,而是函数),还有一个比较大的问题,就是虽然bottom half在一个CPU上是串行的(由local_bh_count[cpu]记数保证),但是在多CPU上是不安全的,例如,一个CPU上在运行关于定时器的bottom half,另一个CPU也可以运行同一个bottom half,出现了重入。
2.4.1中的bottom half
2.4.1
中,用tasklet表示bottom half, mark_bh就是将相应的tasklet挂到运行队列里tasklet_hi_vec[cpu].list,这个队列由HI_SOFTIRQ对应的softirq来执行。另外,用一个全局锁来保证,当一个
CPU上运行一个bottom half时,其它CPU上不能运行任何一个bottom half。这和以前的bottom half有所不同,不知道是否我看错了。用
32个tasklet来表示bottom half:struct tasklet_struct bh_task_vec[32];
首先,初始化所有的
bottom half:void __init softirq_init()
{
... ...
for (i=0; i<32; i++)
tasklet_init(bh_task_vec+i, bh_action, i);
... ...
}
这里
bh_action是下面的函数,它使得bottom half运行对应的bh_base。static void bh_action(unsigned long nr)
{
int cpu = smp_processor_id();
/*1*/ if (!spin_trylock(&global_bh_lock))
goto resched;
if (!hardirq_trylock(cpu))
goto resched_unlock;
if (bh_base[nr])
bh_base[nr]();
hardirq_endlock(cpu);
spin_unlock(&global_bh_lock);
return;
resched_unlock:
spin_unlock(&global_bh_lock);
resched:
mark_bh(nr);
}
/*1*/
试图上锁,如果得不到锁,则重新将bottom half挂上,下次在运行。
当要定义一个
bottom half时用下面的函数:void init_bh(int nr, void (*routine)(void))
{
bh_base[nr] = routine;
mb();
}
取消定义时,用
:void remove_bh(int nr)
{
tasklet_kill(bh_task_vec+nr);
bh_base[nr] = NULL;
}
tasklet_kill
确保这个tasklet被运行了,因而它的指针也没有用了。激活一个
bottom half,就是将它挂到队列中 :static inline void mark_bh(int nr)
{
tasklet_hi_schedule(bh_task_vec+nr);
}